Kepler Object Manager
STATUS:
 The content in this page is outdated. The page is archived
for reference only. For more information about current work, please
contact the Framework team.
The content in this page is outdated. The page is archived
for reference only. For more information about current work, please
contact the Framework team.
Overview
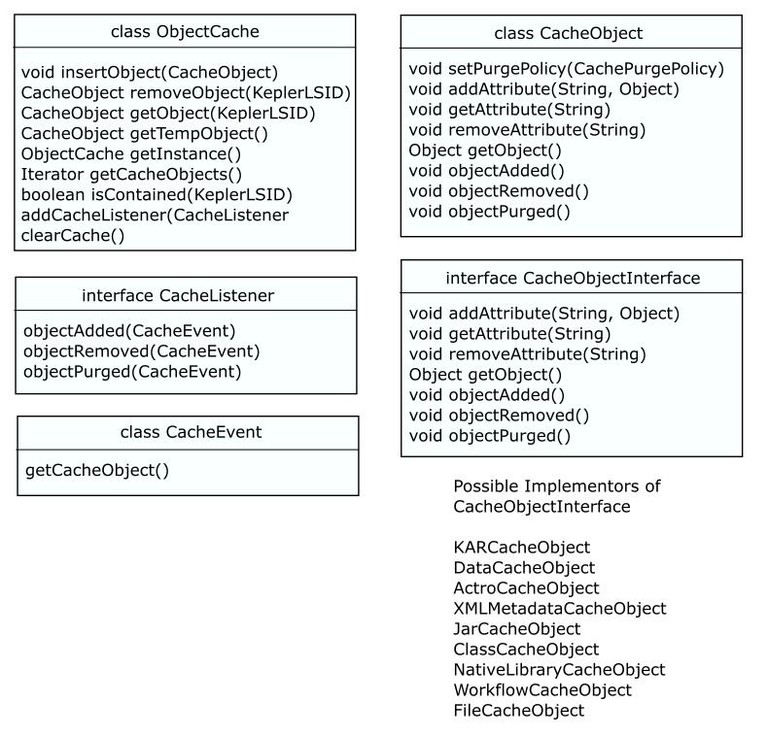
The Kepler Object Manager is the infrastructure component designed to manage access to all objects on both the local filesystem and through network-accessible services. Objects managed include data objects, metadata objects and annotations, actor classes, supporting java libraries for actor classes, and native libraries supporting actor classes. These objects would be managed through a uniform cache manager that can store proxy copies of remote resources and efficiently handle large objects in memory and on disk.
Any or all of these objects can be archived into an archive file called a kepler archive file (kar file). These archive files will be recognized by the Kepler system and can be opened by Kepler, which results in the archive being inflated and any supporting classes and libraries being accessible by a classloader.
Most, and possibly all, objects will be identified using an LSID identifier. This identifier can be used to retrieve more detailed information about the component, including metadata for the component which will include a list of components on which this one depends. Component dependencies SHOULD be able to be expressed as references to kepler archive files, and kepler archive files themselves MUST have a unique LSID that names the archive (the archives LSID is probably stored in its manifest).
Object Manager Use Cases
UC-1) Facilitate the caching of local and remote resources for faster acquisition of system components. The cache should accept a CacheObject from a direct call from within kepler. It should also be the main api used to acquire remote objects via LSIDs. A call to getObject(LSID lsid) should retrieve the object pointed to by the lsid and cache the object locally as well as provide api support for using the object. All save/open type operations will also be controlled by the OM.UC-2) Manage LSIDs within kepler. Since all local and remote objects must have an lsid to be useful in kepler, the OM should make sure that 1) LSIDs are unique in the system and 2) that LSIDs actually resolve to an object.
UC-3) Handle adding/removing system components. The OM should notify relevant objects when components are added or removed from the system. This should enable the easier adding of Actors and other components to the Actor Library.
Object Manager Functional Requirements
FR-1) Must allow heterogenous types of objects to be cached and accessed via an LSID.FR-2) Must allow components to be retrieved from remote repositories via an LSID.
FR-3) Must allow local components to be stored and assigned an LSID.
FR-4) Cache must be persistent across kepler sessions.
FR-5) CacheObject must be extendable to allow different types of CacheObjects to control their lifecycle events.
KAR File Use Cases
UC-1) Facilitate transport of workflows to grid/distributed/server/p2p systems. Scientist builds workflow on local system. S then does some clicking on UI to have workflow execute on remote system. The local system determines the components (actors, directors, libraries) necessary to execute the workflow. This is transferred to the remote system. If the remote system does not have all the components, it will request copies of the components (from repository or from local system) and make them available to the process which will execute the workflow.
UC-2) Preserve an analysis to allow replication, examination and further experimentation. Scientist builds workflow which does something magical. S does some clicking on the UI and the entire workflow, datasets, dependencies, initial configuration, etc, is perserved in a file. This file can then be loaded on another computer and the analysis reexecuted.
UC-3) Allow the development and distribution of components (actors/directors) which can be released on a schedule independently from Kepler itself. Scientist/developer determines that in order to perform a certain step in a workflow, new binary code is required. S/d develops a Kepler actor using the Java language (and perhaps jni stubs into a native library). This actor can then be distributed to another Kepler system which will be able to utilize it in workflows.
KAR File Functional Requirements
FR-1) Mechanism to package resources required to implement a component in kepler system.
FR-1a) must be able to contain java class files
FR-1b) must be able to contain native binary executable files
FR-1c) must be able to conatin native library files
FR-1d) must be able to contain MoML and other XML based text
FR-1e) must be able to contain data in binary and ascii formats including zipped data.
FR-2) Must describe the contained components so they can be utilized in a Kepler system.
FR-2a) each component must have a unique LSID identifier which is tied to the specific implementation of the component.
FR-2b) must contain an OWL document with semantic ordering for the contained objects
FR-2c) each component must list its dependencies in terms of LSIDs.
FR-3) Kepler must be able to utilize the components contained within the package.
FR-4) Kepler must be able to detect missing dependencies when loading a packaged resource.
FR-4a) Kepler must alert the user to missing dependencies and provide the user with the alternative to not use the resource or attempt to discover the missing dependencies.
Design Discussion
Because we are trying to balance a relatively short release period with getting the most functionality we possibly can, we are probably going to have to leave out some of the advanced features of the OM/KAR system. The current incarnation of the kar file includes actor metadata, actor class files and dependencies. Since we do not have a custom classloader at this point, including binary code within the kar file is almost worthless because we cannot dynamically load classes that come in at runtime. A pre-release 1 work around for this may be to only include actor metadata in the kar files and allow them to pull classes out of the current static classpath. This would leave the problem of tackling the custom classloader until post release 1.0.
The OM itself currently uses the original incarnation of the DataCacheManager which has been described by multiple people as "a mess". This design of the OM will re-write the cache system and make it much more lifecycle driven. We should also be able to fix current threading issues that seem to exist within the DataCacheManager.
Different Kinds of Kar Files
In order to make the problem tractable, we limit the kinds of kar files into three categories.
"Package" Kar
This type of Kar file is the basis of the binary extension and distribution mechanism. These Kar files are intended to satisfy the Kar Functional Requirement 3 above. They are collections of components developed by a single individual/organization which consists of java classes, java jars, native binaries, native libraries, etc. This is the only type of kar file which can contain these types of components. The package will always be distributed in its entirity and the developing organization is responsible for the individual components to be able to function together while using the same supporting classes.Within the Kar file, each actor/director component will be assigned an LSID for identification and dependency analysis. In addition, each of these contained components will have an implicit dependency on the containing Package Kar file itself.
"Save" Kar
This type of Kar file is intended to be the equivalent of the traditional "save" functionality. The contents of the Kar file will be one or more MoML/XML files which describe the actor/director/workflow along with explicit dependency LSIDs. The intention is if a User takes some standard actor (as supplied by a Package Kar) and changes some ports/parameters/annontations and chooses to save the result, the MoML describing the changes will be saved in this type of Kar file. The Kar itself will not contain any binary components, but instead will have explicit dependencies on the LSIDs for the required components. The Kar can have dependencies on another Save Kar if necessary.The Save Kar can be reloaded on another workstation but will only be functional if all the explicit dependencies are satisfied.
"Archive" Kar
This Kar file will essentially be a conglomeration of one or more of the other two types of Kar files. Ideally it should be required to contain at least one Save Kar for otherwise it is nothing more than a collection of Package Kars. The structure of this Kar file will be explicit unmodified copies of the other Kars themselves along with the Metadata for each of the contained kar files (but not the elements within those kars). An example might be:
- /META-INF/MANIFEST.MF
- /package1.kar
- /package2.kar
- /savewf.kar
Sample Dependency Diagram
The following diagram shows an example of the dependencies. In this diagram there are three Package Kar files represented by cubes. Each of these Kar files has multiple actors/director components within. There are then three Save Kar files represented by rectangles labeled "<<component>>." (This label is an artifact from the diagramming tool used.) The large irregular shaped outline represents the result of creating an Archive Kar from the Workflow Kar at the bottom. Every Kar file in the diagram is then copied into the Archive Kar file.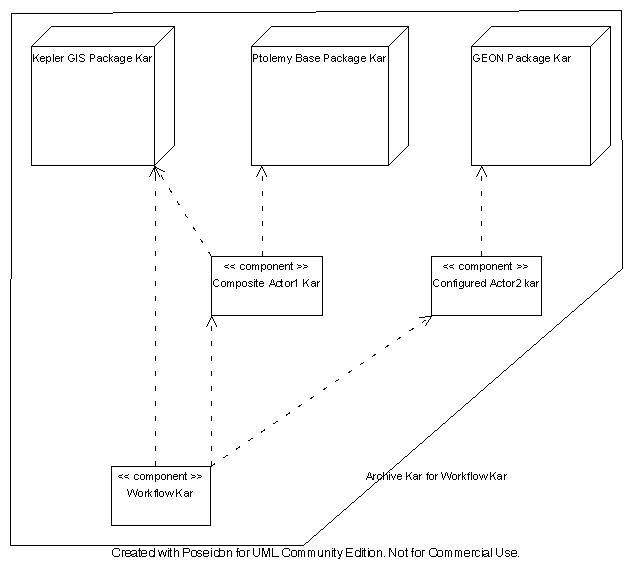
Classloader Discussion
The intention is that each of the Package Kar files will have its own classloader and hence allows for isolation of java components contained within. This does not prevent actors from multiple Packages from collaborating in a single composite actor/workflow but does prevent naming clashes from happening.One benefit of this is there will be a fairly small number of classloaders present in the system. Every instance of actors in the same Package kar file will share the same classloader. The advantages of this (over having a different classloader for each individual actor in the system) is a reduction in runtime bloat.
There will eventually be some duplication of 3rd party jar files within package kar files. Even though this will lead to some disk storage and runtime bloat, this must be weighted against the complexities of the alternative where packages can share individual jar files.
Overall, I (ksr) believe the two points above taken together will result in a system which is implementable, flexible, and resource friendly.
Inter-Package and Circular Dependencies
The first question is if there can be dependencies between two different Package Kar files. Such dependencies could arise in the following ways:
- MoML based actor contained in a Package Kar. For example, a Ptolemy Base Actor might have some specialization which is useful within the context of a package.
- Others???
A MoML specialization of another actor could be accomodated by having the package developer deliver two different Kar files, one for the binary components and another for the MoML based components. This might cause some confusion and additional complexity for the developers however it does remove the requirement to support dependencies among Package kars.
There could be problems with circular dependencies among the Package Kars and the classloader strategy. The complexities are not known and there might be ways to work around them. It might be the case that the Package Kar loader can detect a MoML only actor (with binary dependency on another package) and simply utilize the other package's class loader. This would be the ideal situation.
Circular dependencies among Save Kars should not pose a problem.
Object Diagrams